
我来给这个专栏除草啦!这次介绍一个算法Majorization-Minimization (MM)。MM可以作为一个理论框架,但是我们这次不涉及收敛性什么的,就说一下在工程当中如何去应用它,包括一些构造技巧以及在机器学习和通信中的应用的例子。
本文分成一下几个部分:
Part I: MM算法原理
Part II:用MM导出经典算法
Part II.A:泰勒展开法 -- DC Programming, Gradient Descent, Cubic Regularized Newton
Part II.B:凸不等式 -- Expectation Maximization
Part III: 实际应用例子
Part III.A: 机器学习 -- 稀疏优化
Part III.B: 通信 -- 智能反射表面、MIMO系统
如果有啥没有说对的欢迎指出来,因为能力有限,之前也没有用过MM,所以如果有哪里错了请一定指出来!
Part I: MM算法原理
MM主要的思想呢就是非凸函数太难最小化了,我就构造几个简单的子问题分而治之。原理就是下面这张图
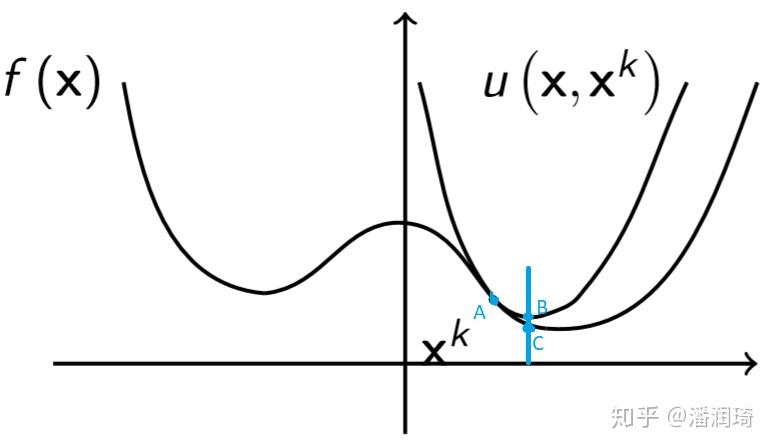
假设 在A点,函数f很难最小化,我们就构造一个好优化并且在它上面的函数u,我们找到u的最小值B点,在下一步
移动到和B横坐标一样的C点,用表达式写出来呢,就是
其中 是可行域。
为什么u要在f上面呢,因为我们想让函数值下降,如果u在f的上面,我们可以保证
从图上看呢,就是C点比B点低比A点低。这么一来,目标函数的值就不会上升了,我们期望它能下降,原理就是这么简单。算法也很简单

Majorization-Minimization的名字就是这么来的,找一个在上面的函数u——Majorization,最小化函数u——Minimization。
Part II:从MM中导出经典算法
虽然MM原理简单,有不少经典的算法可以用MM构造出来,我们能构造出很多经典算法,我们借着这个介绍两种MM中构造u函数方法——泰勒展开和凸不等式。
Part II.A:泰勒展开法 -- DC Programming, Gradient Descent, Cubic Regularized Newton
构造出来的函数u必须是好优化的,那么我们就想咯,一次函数和二次函数挺好优化的,再加上u和f需要在A点相切,我们就用泰勒展开咯。这里的阶数是按照[0]里面定义的,可能有点儿奇怪。
一阶展开 -- Difference of Convex Programming
我们只泰勒展开一次项并且保证在函数上面,那就只有凹函数了,凹函数也就是反着的凸函数,它们长这个样子
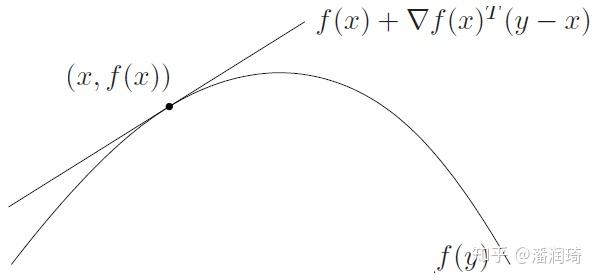
我们怎么应用这个性质呢,考虑下面一个非凸优化
我们看到f(x)是凸的,如果g(x)也能变成凸的整个问题就是一个凸优化问题。考虑到g(x)的线性展开总是在g(x)的上面,那么我们就可以用一阶展开对g(x)进行Majorization,MM的算法如下,每次迭代解一个凸问题:
这也就是DC programming[1]以及如果第一项f(x)=0的话就是generalized power method[2],如果 是Stiefel manifold的话就是最近马毅老师力推的matching, stretching, and projection[3]。
二阶展开 -- Gradient descent
对于一般的函数,一阶展开并不会始终在函数的上方,那么要怎么办呢,那就加一个正数(二次项),使得一阶展开加上这个二次函数在函数的上方,假设原函数是 ,一阶展开和加了二次函数的图长这个样子
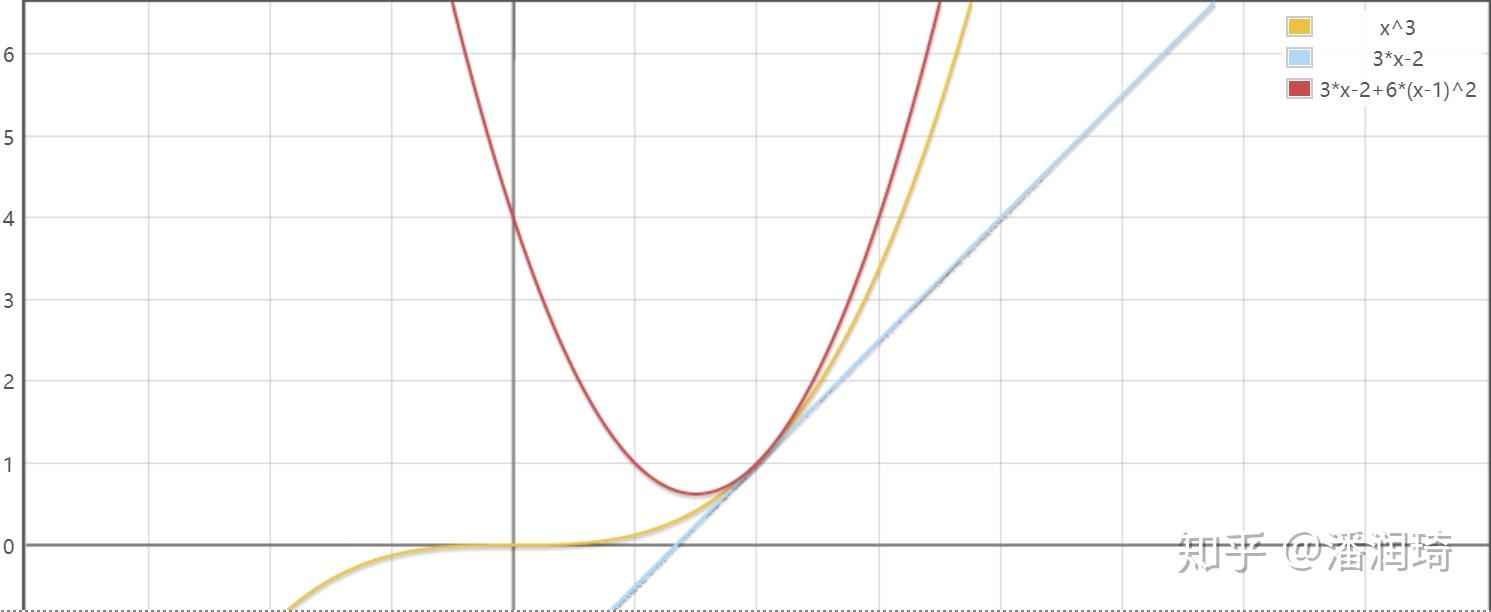
可以看到,在可见范围内,一阶展开始终在原函数的下方,并不满足要求,但是加了二次函数就满足要求了,MM算法如下
这个东西又恰好是我们熟悉的梯度下降,推导过程也很简单,令 ,求出g(y)导数等于零的点也就是
化简出来也就是 ,也就是我们熟悉的梯度下降方法。如果在目标函数上加一项不可微的函数,那就是近端梯度下降啦[4]。
三阶展开 -- Cubic Regularized Newton:一阶二阶都是著名算法,那二阶泰勒展开加个三阶项怎么样?这就变成了Cubic Regularized Newton[5]。它长这个样子
这个方法也是一个最近的热点,在这里推销一下专栏编辑 @Zeap 关于这个优化方法的文章[6.1][6.2]。
Part II.B:凸不等式 -- Expectation Maximization
还有一类就是用一些不等式放缩比如琴声不等式,可以用MM推出著名的EM算法。这个方面感觉文章[0]的ppt讲得特别好,这里就懒一下直接放截图啦。


Part III: 实际应用例子
Part III.A: 机器学习 -- 稀疏优化
我们知道如果要让一个东西变得稀疏,我们去最小化它的0范数,但是零范数又太难优化了,我们就去最小化一个凸函数1范数,其实1范数和零范数差得挺多的
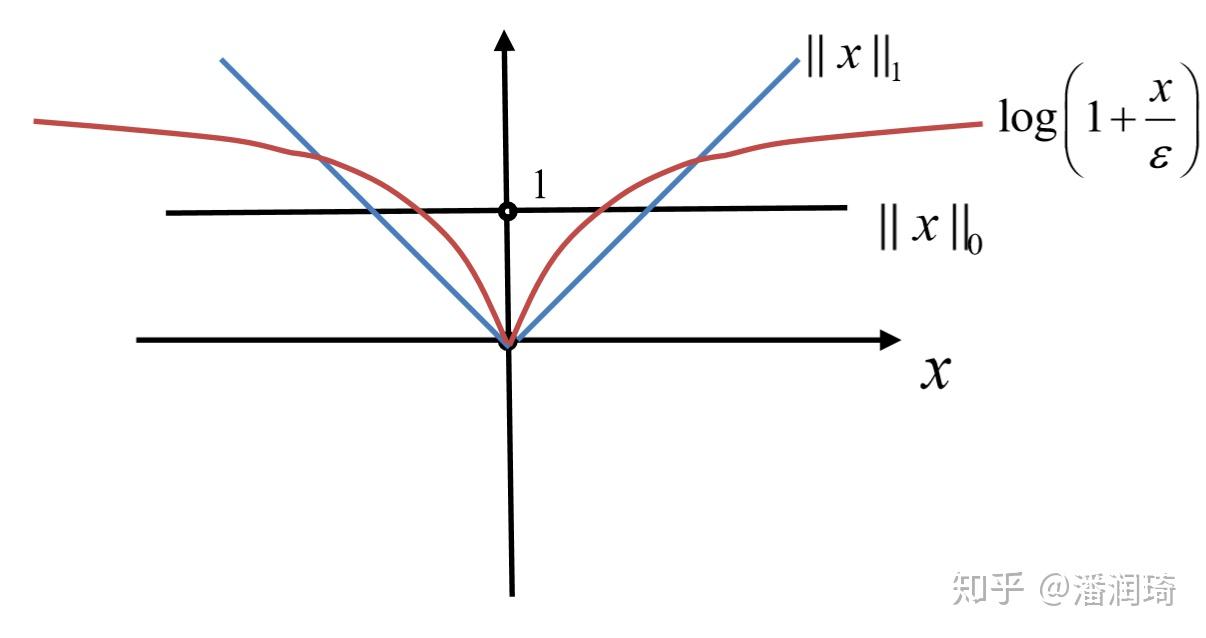
相比较于1范数,这个 更加像0范数一点儿,所以它诱导稀疏的能力会更强一点儿。虽然它既不是凸的也不是凹的,但是可以注意到
是一个凹函数,一阶展开始终在它上面,我们就可以用上面所说的一阶展开的方法进行Majorization。
在这个例子里面,优化问题是 ,注意到
是一个凹函数,按照前面DC Programming的方法,MM每次去最小化一个一阶展开
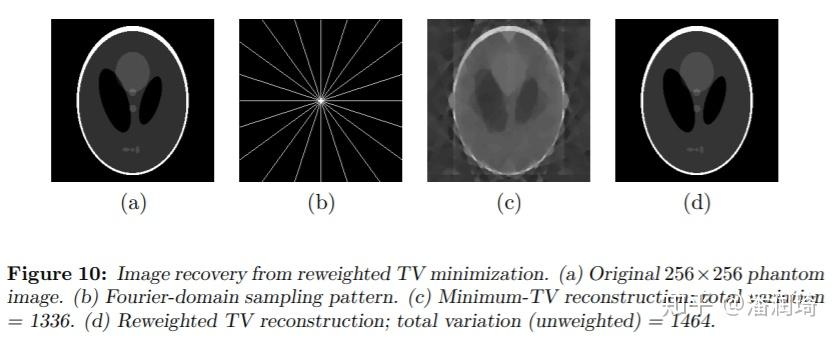
其中 表示第k轮迭代的变量的第i个分量。这个就是著名的reweighted l1 norm minimization[7]。效果上比直接最小化1范数好了很多呢(a是ground-truth,c是1范数,d是reweighted l1)
Part III.B: 通信 -- 智能反射表面
我在写这篇文章的时候,想找一个机器学习以外的比较热应用,然后找了好几天没找到,就去看去年通信和信号处理会的best paper里看有没有,终于找到了一篇用MM的[8](MM算法和详细推导在paper的第四页)。具体背景我也看不懂,大概是要最大化一个类似于SNR的比值,直接看优化问题吧
其中 都是正定矩阵,那个约束条件是因为那个v是个反射角,有
所以会有那个模长是1的constraint。因为是最大化,所以在MM过程当中想找一个函数从始终在原函数的下面。令
,可以看到目标函数对于
是凸的,一次展开式在原函数的下面,对
展开得到
对于模长是1的constraint来说,第一项是一次项很好优化,第二项是二次项有点儿困难,所以我们继续对 进行Majorization(找一个在它上面的函数)。对于厄米矩阵
我们有
取 我们就可以接着推导
可以看到g(v)是一个关于v的线性函数,优化很方便,MM的迭代如下
这里用MM也是比Block Coordinate Descent快了很多
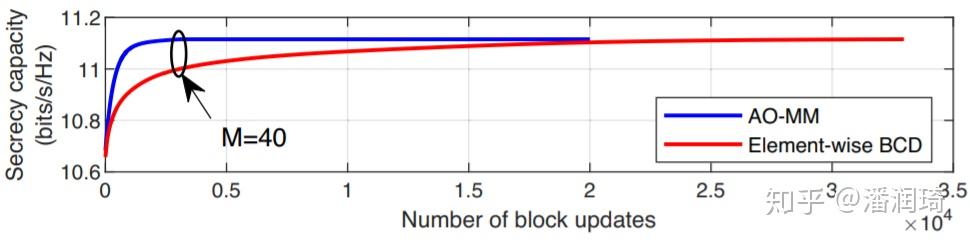
这两个例子都显示了MM简单而powerful,所以呢,在工程当中应用MM是一个非常不错的选择。
2.28 更新:
MIMO系统:这里还有一篇MM大佬Palomar教授组里的文章,讨论了雷达通信mimo系统中能量谱匹配,组合了各种MM技巧解决了一个实际问题,有点儿复杂,有兴趣的也可以去看一看[9]。
最后如果大家对MM感兴趣的话强烈推荐大家去看这篇文章,里面讲了很多的构造技巧以及应用
Majorization-Minimization Algorithms in Signal Processing, Communications, and Machine Learning[0]Majorization-Minimization Algorithms in Signal Processing, Communications, and Machine Learning
[2]Generalized Power Method for Sparse Principal Component Analysis
[3]UNDERSTANDING ?4-BASED DICTIONARY LEARNING: INTERPRETATION, STABILITY, AND ROBUSTNESS
[5]Cubic regularization of Newton method and its global performance
[6.1]Cubic Regularization with Momentum for Nonconvex Optimization
[6.2]Convergence of Cubic Regularization for Nonconvex Optimization under KL Property
[7]Enhancing Sparsity by Reweighted ?1 Minimization
[8]Enabling Secure Wireless Communications via Intelligent Reflecting Surfaces
[9]MIMO Transmit Beampattern Synthesis Under Waveform Constraints: A Unified Approach



 网站首页
网站首页 九游会简介
九游会简介 新闻动态
新闻动态 九游会注册
九游会注册 九游会登录
九游会登录 APP下载
APP下载 代理加盟
代理加盟 咨询投诉
咨询投诉